
AIphee Lavoie is one of astrology’s most creative and inventive practitioners. He was born on October 7, 1934, at 8:04 p.m. (time rectified through his conversations with family members) in Grand Isle, Maine” the northernmost part of the state, less than half a mile from the Canadian border. (See Chart, below.) His first language is French; he didn’t learn English until he was 18 years old. For the past 42 years, Alphee has counseled individuals, helping them to find them selves through the unsurpassed science of astrology. To be of better service to clients, he has written specialized computer programs that he later made available to astrologers so they could hone their skills and bring awareness to their own clients. He has done pioneering work in the fields of horary astrology, predictive techniques, rectification, financial astrology, and the use of artificial intelligence in astrology software. He is the research director for NCGR and spearheads advanced research in astrology. Alphee lectures world wide, writes a monthly column for Dell Horoscope magazine, and continues to develop astrology software under the auspices of his company, AIR. Software. His many astrology programs include Millennium, perhaps the foremost astrological toolbox of predictive techniques, and the celebrated Market .Trader financial astrology software. He is the author of several books, including Horary Lectures, Lose This Book …and Find It through Horary, and Horary at Its Best, and two DVD lecture series, one called “Horary” and a second called “Counseling Workshop.” Alphee has devoted his life to bringing the aware ness of astrology to the public eye as well as into mainstream institutions. His passion is to continue to improve astrology and make this science the very best it can be by finding out what really works and what doesn’t. Alphee can be contacted via e-mail at: alphee@alphee.com, and you can visit his Web site, ww.alphee.com, which features a library of articles and research. studies.
I interviewed Alphee by telephone during the first two weeks of November 2004.
Hank Friedman: Alphee, how did you get into astrology?
Alphee Lavoie: I hurt my knee and was in the hospital for a while: A nurse brought me Casting the Horoscope by Alan Leo. It was the funniest thing. At that time, I had only graduated high school. There was some trigonometry to do, and I didn’t know how to do trig. The nurse said the doctor will come around and show you how. The doctor came around one day and showed me how to do it, and I cast my first horoscope.
HF: And how did you get into astrological programming?
AL: I got into programming back when I had my first Radio Shack computer. .I bought the computer and plugged it in. I typed in 1 + 1 = and pressed the Enter key. It displayed an Illegal-something error message. I thought, This thing doesn’t work. I called the guy at Radio Shack and said, “You sold me a computer that doesn’t work.” He said, “That’s not the way it goes. Type in A = 1 and B = 1, and then add A + B.” I said, “Oh my God.” That’s how I started programming. I had thought it was like a calculator.
HF: Why did you have the need to create astrology software?
AL: Years ago, in 1965, I quit my engineering job and went into astrology full time. I did everything by hand then. There were no cal- culators. But when I got into programming, I found that there were a lot of calculations that I
needed, to be an astrologer. At that time we had Win*Star and Nova. Those were great programs. But I thought I could do more, so I developed my own program. This is how I started.
HF: What do you want readers of The Mountain Astrologer to understand from all your years of doing astrology?
AL: When a person comes to see you, he doesn’t say, “Gee, my life is so good, tell me what the hell is going on.” People come and see you because their life is just gone (they have big problems). They really believe in what you have to say and listen very carefully.
The problem we have in astrology today is that there are so many techniques out there, and there are so many books that have been written, and half of it is junk. My feeling is that we need to become more aware of what works and what doesn’t work, because we don’t know how much we can screw up people using a technique that doesn’t work.
This is my thing. That’s why I started my Astro Investigator research group, and we have a Web site for them, too: www.astroinvestigators.com. It is open to the public, and we invite everyone to come take a look and participate. We all need to test techniques to determine that, yes, this method works; this one we’re not sure of. So then, a young astrologer can go to the Astro Investigator Web site and see that all the people doing research found this technique to work very well. Then at least they’ll be using techniques that we have proved to work, scientifically. That’s my goal for all time.
HF: Tell me about a new technique that you’ve come up with.
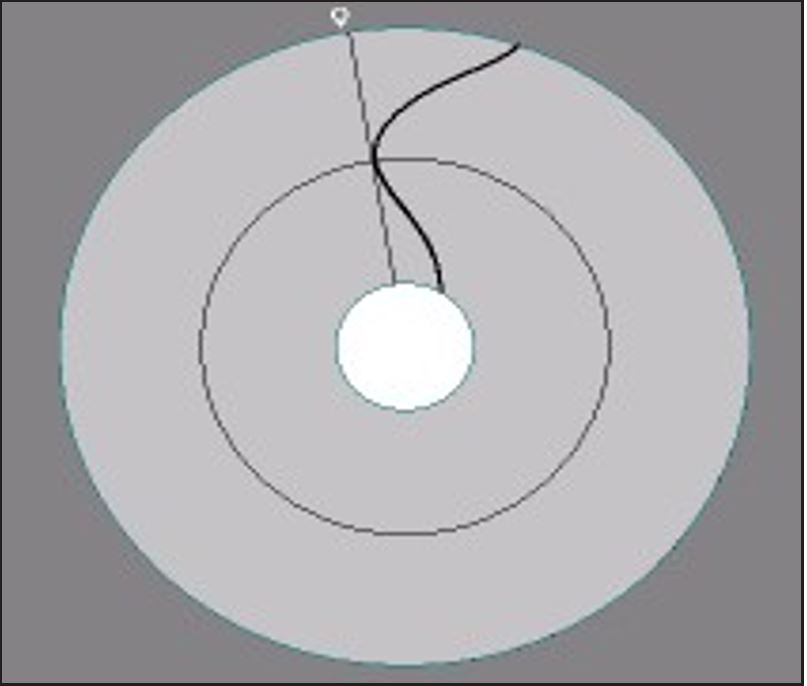
AL: Let’s say that you’ve lost something. You’ve looked all over and are upset because you can’t find it. Go to your computer and do a horary chart for the moment, at your locality. Then look at the ruler of the 2nd house (because 99% of the things we’re looking for are represented by the 2nd house). For example, if the 2nd house cusp is Taurus, then its ruler is Venus. Create a local space chart on your computer, print it out, and place it in the middle of your house. It’s going to show, let’s say, Venus at 30 degrees from North. Point toward that Venus direction and also in back of you on that line. (Einstein said that if you start at one point and keep going in space, you come back to the same point again.) Ninety-nine percent of the time you will find what you’re looking for. [Interviewer’s Note: To use a local space chart to locate a lost object, place it on the floor, align its North with North at your location, and then look in the direction where the planet representing the lost object is placed.
Figure 1, Local Space Chart
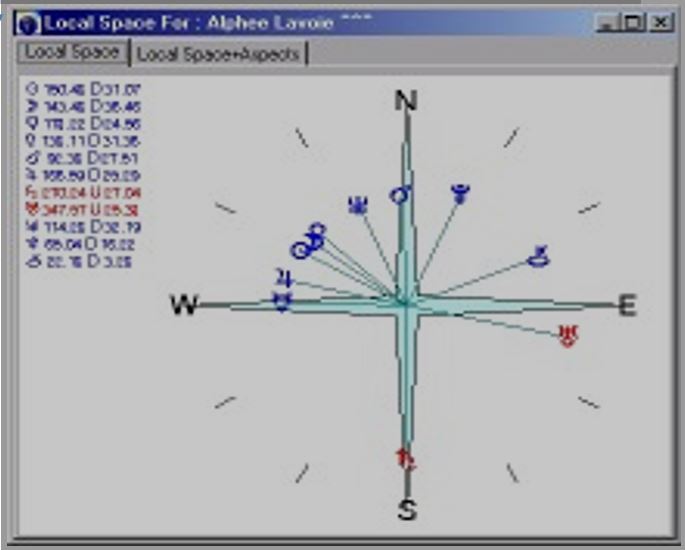
For example, we were at an astrology conference in Toronto. A person lost an expensive gemstone earring. Four different astrologers were looking all over the hotel, going in one direction and another. According to the local space chart, we then looked 35 degrees from East and found the earring. Another thing: The more that the planet you are looking at is below the Earth, the closer the lost item is to the floor. The higher the planet is in the sky, the higher up the object is. This is one of my best discoveries.
HF: What di you see as the purpose of astrology?
AL: I think astrology is one of the best tools that God has ever given us. We know that the universal clock is exact. You can set your telescope, and ten years from now, Saturn is going to be there. Exactly there. I always tell people that God can’t say to you, “You’re really screwing up down there; you better straighten up your act.” It starts working on the inner level. You start feeling uncomfortable. You start feeling: my life stinks, my partner is this, etc. That’s why you can’t beat astrology to tell the person where they’re at.
For example, a client comes in, sits in my counseling chair, and says, “I want to get a divorce. I want to quit my job. I want to move to Alaska.” Something triggered all of these feelings. So you go to the chart. And you’re not going to see that Saturn is the problem because if it were Saturn, the client would know exactly what to do. It’s either Uranus, Neptune, or Pluto, because when these planets are active something happens, everything falls apart, we can’t pigeonhole anything because it doesn’t work very well on the physical level. It works more on a soul level. You’re able to say, “look, did it start at this point with a partner or a job?” You can see Uranus or Pluto hitting a point; this is where it started: “You started being unhappy there.” Then you can work on it with the client. “If you can straighten this out, your job will get better.” And they’ll call you back a month later and say, “You straightened out my whole life!”
Here’s a touching story: last Christmas, my wife Carol and I were putting up the Christmas tree, and a beautiful young woman rings the doorbell at 10
p.m. She gives me an envelope and asks, “ Are you Mr. Alphee Lavoie?” I say yes. She says, “I owe you this” and walks out. We open the envelope, and in it is a check for $1,000, with a letter that reads: “When I was 18 years old, I went to see you. I heard about you. I had no money. You saw me about five times. I was on drugs. I was a prostitute. Today I’m married. I have two kids. I live in Colorado and my life is beautiful, thanks to you. I still listen to your tapes, and this is what I owe you. I wish I could give you more.” I literally had tears in my eyes. This is what astrology can do.
HF: How do you counsel clients?
AL: Let me tell you. The biggest problem with astrologers today is that they say, “I see this in your chart, so you’d better do this and you’d better do that.” We’re not in this business to run people’s lives. We’re in this business to say, “You’ve got a choice. If you take a right here, you may end up here. Or you may end up there. But it’s not a good time for you to take a left right now.” When people ask me, “What would you do in my situation now? I want to quit my job,” I say to them, “If you looked at the way I ran my life, you would never ask me that.”
HF: Shall I quote you on that?
AL: Yeah, you can quote me on that. You can’t make a decision for your client. That’s the biggest fault of astrologers. What some astrologers are trying to do is to force someone to do their thing. Let the people feel it in their hearts, feel the energy, and make a decision, saying “Gee, I made the decision and it’s great.” It gives them strength. .
HF: So, you’re giving them the information and they make the decision.
AL: That’s it. You give them all the information, and you point to good times and bad times – times when they need to reflect and not act and then let it go.
HF: Let’s say you look at someone’s chart and it looks absolutely horrible for the next month. What would you do?
AL: I don’t hide anything. I would say to them, “Look, from this date to this date …” and then I’d explain the things that could go wrong. I would tell them, for example, “Take care of your health.” I had a woman client whose 6th house and Ascendant were very afflicted. Everything was hitting them within a week. I said to her, “I don’t feel right about this. I feel you’re going to be overworked or overreacting or not eating right. If you don’t feel well, see a doctor, because there are a lot of things going on here that might be missed.” She did, and she found out that she had Hodgkin’s disease. And that they could cure it.
HF: What astrological factors do you focus on most? For instance, do you focus on the basic planets, fixed stars, asteroids?
AL: I’ve studied all of those. In 1965, I divorced my wife, and the court gave me all my kids. I quit my job because I needed to take care of the kids. By that time, I had studied a lot of astrology. But even then, what I focused on most were the regular planets, the regular aspect; I didn’t get too much into noviles and quintiles. Although I think they work, I didn’t use them in my readings. I use transits, progressions, and solar arc directions.
If somebody wants to start a business or is saying that their life is a mess right now, and I can’t totally understand it using the basic chart, then I will do the Alphee Twist or use some other technique. But as you know, when I did client work (which I stopped in 1996), I was counseling six clients a day in my office. I was only working for an hour with each client. I didn’t prepare; I had a girl who prepared charts for me. The person would come in, and I would go to work with the chart. That’s all I used. I could get all the answers I needed to help people just with that.
HF: You use many different predictive techniques. How do you sort out all of the predictive events that are going on?
AL: Here’s the way I sort it out: Transits are definitely events that work on the inner level of you the things you see on the outside that make you reflect on the inside. Transits, of course, are very acute. Transits are the events that we are reflecting on our own. Uranus comes on your Venus and you say, “I hate my wife. I hate what I’m doing. I hate this.” Things haven’t changed; they have been that way forever. Why is it now that it bothers the hell out of you?
HF: It sort of lights up that part of your chart, so it’s a really conscious thing.
AL: Totally. We live our transits. Transits are conscious. The way I see it, also, a secondary progression is something going on inside of you. You can feel it, but you don’t really know how to react to it.
Solar arc directions, on the other hand, are almost something out of your control. Something that comes ‘through other things. This is why you can rectify a chart with solar arc, using events like divorce. A month before, you didn’t think you were going to get a divorce or a separation.
HF: Solar arc events are more external?
AL: Much more external.
HF: Are you saying that solar arcs are the most uncontrollable outer things?
AL: Solar arcs are unconscious. If you have a bad solar arc, be very careful. One time, my wife Carol got beat up and her money was stolen. But what happened? Solar arc Mars was squaring her Neptune. She went shopping for Christmas, about five years ago. She had a lot of money with her. She saw two men circling around in their car. They stopped, and she asked, “ Are you lost?” The guys got out of the car, beat her up, and then took her money: Mars Neptune. She should have run like hell. Being an astrologer, she should have known that when Mars squares Neptune, you don’t trust anybody because somebody is going to take out their aggressiveness on you.
HF: Let’s look at some of the techniques you have created and added to your software. For example, why did you develop the Time Tunnel?
Figure 2: The Time Tunnel:
AL: You can see things really quickly with the Time Tunnel. Years ago, we used to spend two hours to prepare before the client came. When your business gets to the point that you are seeing six people a day, and you spend an hour on each client, you can’t really do that. I really was thinking about stopping flipping through papers. What I find is that you miss a lot of stuff by doing that. You can miss stations. For example, Saturn might come along and
station alongside Venus and you wouldn’t see that. (See Figure 2, The Time Tunnel: Saturn Stationing on Venus, above.) HF: How do you use the Time Tunnel?
AL: Usually I work with the fourth and the sixth harmonics, the fourth showing the bad events and the sixth showing the nice events. You can calculate a Time Tunnel for a year, and looking at it, you can see Jupiter crossing Venus three times in the sixth harmonic. It shows Saturn making a station on a person’s Mars. You can see the starting date because the outside of the Time Tunnel circle is today. When you see a crossing of two or more lines, you can click your mouse on it. The program then displays everything else that’s happening that day. That’s a very valuable thing because you can see not only Saturn making .a station or even squaring Mars, for instance, but when you click on the intersection, all of a sudden you see three other aspects working at that time, which would intensify the Mars Saturn event. What I like to do with this, also, is to calculate the tertiary and minor (both direct and converse) progressed lines, all at the same time.
HF: How do you use them?
AL: For example, a client is having a hard time because Saturn is squaring her Mercury, and Mars is coming around and conjuncting her Mercury. Saturn Mercury: I’m depressed, and Mars is intensifying the fire. At the same time, by clicking on the Time Tunnel, you see other aspects. Venus is squaring the Ascendant, and now you can say it has something to do with other people because when Venus squares the Ascendant, it also squares the Descendant. So, you can bring together a whole story. And when you see what I call hot points in a chart, you can say that on November 15 there’s a lot of intense aspects; then, when I do my tertiary progressions ( converse and direct together) , I can see around that point what is intense during the middle of November say, November 14-16. I can start seeing that, and then I can put more intensity into it. That is what I call the Alphee Twist. We know that something is going to happen in your life if a tertiary direct planet line crosses an angle of the tertiary converse; that’s definitely the day that an event happens.
A friend of mine just had a bad car accident. He called me up and said, “I don’t see too much happening, Alphee, I don’t know why this accident occurred. “ When I put it on the Time Tunnel, I could see that the tertiary direct Mars was exactly on the Ascendant of the tertiary converse. Not only that, the Moon was on the converse Ascendant. So, it brought in the Moon-Ascendant of the converse, and Mars came and triggered that, and bam! Exactly. No orb.
HF: You’re saying that when converse and direct tertiary lines cross, the event takes place?
AL: For instance, let’s say you have transiting Saturn square Mars, and you know that somewhere along the way, your life has just stopped, and you have to redefine the energy that you put into your life. You are at a cross- roads: Mars. “I’m sick of this, I’m not going to do it.” Or “I’ve got to do more of that.” So now, when you see the tertiary planet come in and cross an angle, at that point (some planet crossing the other one’s angle), it’s going to trigger action.
We act on pure emotion. On that day, you’re going to say, “That’s it. I have to react.”
HF: When you say “crossing an angle,” do you mean crossing another line?
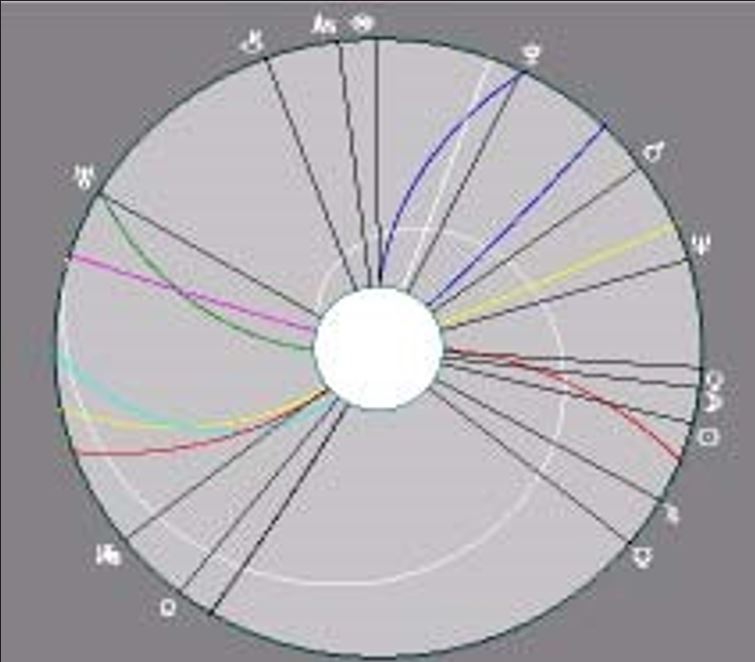
AL: Crossing another tertiary progressed line. (I’m not even looking at the natal chart at that point. ) When you look at the Time Tunnel, you can see that the Midheaven is blue [bold lines, in this illustration] and the Ascendant is red [dashed lines].You can see when a planet crosses one of these angle lines, and to see the exact event, you click your mouse on the crossing, and it tells you that, for example, this Midheaven is squaring Mars, and when it’s going to happen. In looking at the Time Tunnel for direct and converse tertiary progressions, you can see one Moon (e.g., direct) twists in one
way, and another Moon (e.g., converse) twists in the other way. And you can see the times that they cross each other. In other words, if the two lines of the Moon cross each other right on the Ascendant, this is going to be a really intense time, because the two lines of two Moons are crossing the Ascendant at the same time. That’s going to be powerful because you have’ both Moons ( emotional stuff) crossing a personal point. When you see that, it’s very important.
HF: How do you use the Time Tunnel optimally?
AL: What you want to do is to take the Scan To Natal out, so you can just focus on Scan To Scan. This lets me see the tertiary Moon con- junct tertiary Mars. These are the crucial times, when planets cross each other like that.
HF: Essentially, what the Time Tunnel allows you to do is to look at the impact between, for instance, tertiary direct and tertiary converse progressions in order to isolate significant times in a person’s life.
AL: The more crossings you have, the bigger the event. We astrologers know that some- times one aspect doesn’t trigger something, but when you have five or six crossings, this will be a major impact. Without the Time Tun- nel, you could never see these interactions.
HF: I know that you have also pioneered using planetary phases in prediction. Will you talk about that?
AL: One time, there was a discussion in the NCGR group about teachers. A woman there said, “If I don’t have the Moon in the 12th house, I’ll never be a teacher because I know five teachers who have their Moon in the 12th house.” We tested this idea by collecting charts for 840 teachers, and it turned out that the least frequent house placement was the Moon in the 12th house. But what we found that was statistically significant was that most teachers had Mercury in the disseminating phase. And this woman had a disseminating phase Mercury.
HF: How are planetary phases calculated?
AL: They are calculated by the relationship of Earth and the planet. If you look at a planet in a telescope, you can see different phases. Especially with Venus, you can see different phases as you look at it. The planets have to be viewed from Earth. The Millennium software allows you to make a transit search of these phases. We can see that when a certain phase occurs, such as when a Venus phase conjuncts a Jupiter phase, this is going to be a very lucky time. A lot of people get married when a Venus phase is conjunct or opposed their Sun. In other words, let’s say you were born under a New Moon phase. When Venus transits to its New Moon phase, then you have phases in conjunction.
It’s incredible. It’s something brand new, and it’s something that we brought in because it works so well in stock market analysis. Many times, I will choose optimal times using these phases and make a prediction based upon them.
HF: Do you think phases are important for natal work?
AL: As astrologers, we were very molded to using the aspects. We never look at phases. This is something I am trying to bring out looking at more than what we have been looking at. I am sure that if you have a fast Mercury or a slow Mercury, it would have something to do with the way you use your brain or maybe even what you’re interested in reading or not reading.
HF: I appreciate what you just said very much. What else have you noticed?
AL: A fast Moon and whether Mercury rises before the Sun or after the Sun are very important. I found that out in doing research. One thing that I discovered is that the vocational indicator the planet that rises before the Sun indicates what your career is. When we researched career factors, that was the most significant thing we found. Teachers had the highest incidence of Mercury rising before the Sun (with real statistical significance). Musicians had Neptune rising (before the Sun); artists had Ve:nus rising. Managers had Saturn rising before the Sun. We’re looking at the planet that immediately rises before the Sun. With military people, Jupiter was rising before the Sun; it wasn’t Mars. Remember that, in horary, the 9th house rules army camps, guns, and all that.
HF: One of my favorite techniques in your software is the Dynamic Black Box. I’ll bet most people don’t have a sense of how powerful that is. Why did you add this to Millennium?
AL: I love graphs. With the Dynamic Black Box, you can easily view a year at a time. [Interviewer’s Note: The Dynamic Black Box combines the effects of all of the positive and negative transits to show the overall rising and falling effects of transits over time. See Figure 4, The Dynamic Black Box, opposite.] Figure 4:

HF: How did you choose the weightings for each of the various planets in this tool?
AL: That’s always very tough. I always give more weight to the heavy planets and less weight to the faster-moving planets. I determined some of the weightings as a result of my computer work dealing with stock markets. I examined, for example, the day a stock went down and Saturn was aspecting something. From there, I learned that the heavy planet transits carry more weight than events that only last a day.
HF: What do you use the Dynamic module for?
AL: One thing I do a lot with the Dynamic module is use the Multi BlackBox. [ Interview- er’s Note: This tool shows a graph that indicates the best times for work, play, romance, and other activities for more than one person at a time.] In order to look at the cumulative effect of all transits on several people at once, I can add people there. For example, I add myself, my wife Carol, and my company AIR Software and then look at the graph for career and for money. The graph will show me when the career and money indicators are at the highest for all of us together. When we take a vacation, I use this graph, too. I add myself and my wife and see: Wow, we are both very high here, and we’ll take a break then. It’s much more easily done than trying to flip through charts.
HF: There are some items in the new version (5) of Millennium that I haven’t seen before. What is a Key Points Diagram?
AL: This is a great feature. For instance, in my chart I have transiting Mars trining the Moon. I have transiting Mars trining Venus. I have transiting Mars trining the nodes and transiting Jupiter conjuncting the Sun. I can specify any time range, and the Key Points Diagram shows me when each transit happened before and when it’s going to happen again. In other words, this is very good because you can calculate the last time that an event happened and ask your client, What happened then? (See Figure 5, The Key Points Diagram, below.)
HF: What is the Vertical Diagram?
AL: Using Millennium Star Trax, go to the Ephemeris feature. You can
Figure 5:
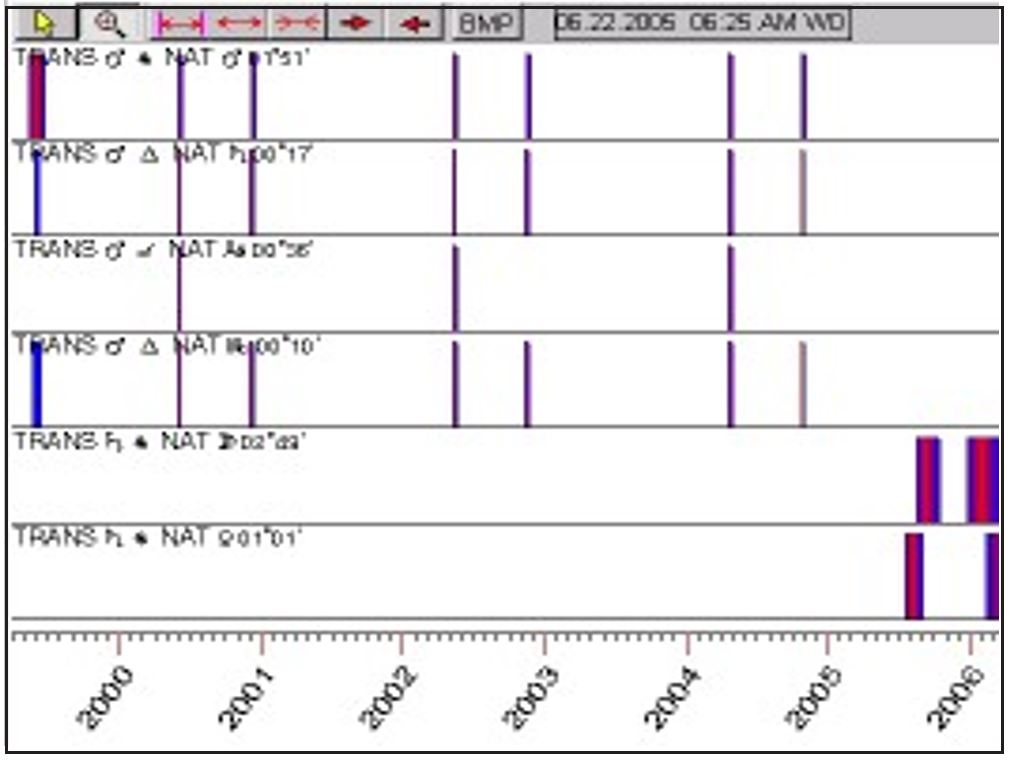
calculate simple transits. You can calculate anything. Once it’s calculated, then you can select the Vertical Diagram. Look down at the bottom right, you’re going to see module
[a.k.a. modulus]. This is initially set at 0. Go to 0-60. As you look at the table, at times you can slide [the horizontal with all of the natal planet positions] down. And then you can see a lot of sixth harmonics in the sky.
When the lines cross, it means you have a sixth harmonic.
By sliding the bar down, I can see that on March 25, 2006, I’m going to have transiting Mercury right on my Neptune. At the same time, I can see that I have transiting Mars and Venus near my natal Saturn-Ascendant con- junction (in the sixth harmonic). Sometimes I want to see things real fast. And in my chart, I can put a year up; then I can slide the bar really quickly and note that I’m going to have this transit and that one. Sometimes some- body is going to call you and say, “Hank, I want to do something in the next two months.” Then you would do that with their chart and slide down and say, “You got a lot of sixth harmonics there, and you have Saturn trining Mercury and all that, therefore I would do it then.” Just a fast way of seeing when a good thing comes up in one’s chart. (See Figure 6, The Vertical Diagram, left. ) HF: You mean, when there are a bunch of convergences?
AL: Yes. And at the same time, sometimes you’ll move the bar down and you can see where a planet hits. Look at me right now. Uranus sextiles Mercury at the same time Saturn trines the North Node, and Mercury trines MidheavenAscendant, all on the same day. This is my chart in January. I see that in January I have a lot of stuff happening on the same day. Sometimes you can see a whole lot of squares in the sky, and let’s say that I wonder if it’s going to hit me. Just do this, and with the mouse, slide your natal bar down to the squares in the sky on the diagram. In seconds now, you can see what the squares will do in your chart. When the aspect is exact, the natal planets on the slide will change colors. Where all these planets are crossing, then they are in square. And if it doesn’t hit you, say fine.
HF: Alphee, I would like to thank you very much for all of your incredible creative work and for taking the time to do this interview for us.
Hank Friedman is renowned in the San Francisco Bay Area for his astrological and transformative counseling work with individuals and couples. His in-depth astrology readings synthesize Western and Vedic approaches. He helps astrology software companies to debug their programs and add new features. Hank is the author of Astrology on Your Personal Computer and reviews astrology software, both online and in periodicals. He has helped to supply thousands of astrologers with the best software for their needs; he represents all major astrology software companies and receives the same commission from each. Contact Hank via e-mail: stars@Soulhealing.com; call toll-free: (888) 777- 7366; Web site: www.soulhealing.com
@ 2005 Hank Friedman -all rights reserved